Il dado, inteso come oggetto a forma cubica tridimensionale con 6 facce, ciascuna identificabile (ad esempio perché contrassegnate con numeri, segni o colori ), esiste da millenni.
Nel corso del tempo ne sono state inventate diverse forme più o meno complesse, tuttavia la sostanza non è cambiata ed è comune a tutte le civiltà antiche e moderne.
La ricorrenza in tempi e luoghi diversi suggerisce che il dado sia una risposta ad un bisogno comune; tale esigenza potrebbe esser connessa con la necessità di trovare un modo semplice e rapido per creare un ordinamento casuale, cosa che noi esseri umani non siamo capaci di ottenere facilmente, (data la struttura del nostro cervello che tende a trovare ricorrenze e schemi anche dove non ci siano).
Anche in una società primitiva, la condivisione di uno strumento “generatore” di casualità ha un’importanza primaria in quanto rappresenta una valida alternativa al ricorso alla violenza nei casi di conflittualità interni al gruppo – pericolosa per la stabilità del gruppo stesso.
Ad esempio per definire una gerarchia, indispensabile nel caso sia necessario assegnare dei turni (la precedenza nella scelta dei pezzi della preda) o stabilire chi abbia diritto ad appropriarsi od utilizzare qualcosa di non divisibile (la femmina, il pasto appena sufficiente per un individuo), che eviti il ricorso continuo allo scontro fisico, la cui conseguenza è l’indebolimento di entrambi gli sfidanti.
Dal punto di vista evolutivo costituisce senz’altro un avanzamento in quanto il gruppo che si affida alla selezione casuale (i cui componenti condividono le regole “del gioco”) spreca meno forze in combattimenti tra i propri membri, forze che vengono risparmiate per essere usate in combattimenti con altri gruppi.
La gerarchia ottenuta attraverso il sorteggio costituisce inoltre un equilibrio più stabile; nel mondo animale ad esempio, all’interno del branco l’ordinamento gerarchico si basa su rapporti di forza tra gli individui che lo costituiscono; non essendo “la forza di un individuo” un valore assoluto (cambia infatti continuamente a seconda del grado di salute, stanchezza, età, nutrizione, accoppiamento, emotività, rapporti con gli altri membri del gruppo, ecc. ecc.) l’equilibrio così ottenuto è di per se stesso fragile in quanto influenzato da innumerevoli fattori esterni. Conseguentemente assistiamo a violenti scontri quotidiani la cui finalità è semplicemente l’ “aggiornamento” della gerarchia e che talvolta implicano effetti negativi sul gruppo stesso quale una diminuzione della sua forza totale (per la morte in combattimento o l’invalidità procurata ad alcuni componenti) o peggio ancora una divisione in due gruppi (conseguente alla ribellione di una parte dello stesso).
Possiamo pertanto affermare che l’evoluzione ha portato l’uomo a scegliere un modo meno pericoloso per assegnare una gerarchia.
Troviamo un esempio di quanto affermato addirittura nell’Illiade: scontro violento tra 2 eserciti (il cui esito nefasto per entrambi si cercò poi di limitare con l’introduzione dello scontro tra 2 campioni) contrapposto al gioco a sorte per l’assegnazione delle prede di guerra.
O alla veste di Gesù giocata ai dadi dai soldati romani (membri dello stesso esercito/gruppo che pur dotati di armi di offesa rinunciano ad usarle per definire un vincitore in un conflitto interno al gruppo)
Uso della violenza per determinare una gerarchia tra gruppi venuti a contatto ma scontro figurato (e non violento) tra membri dello stesso gruppo.
1.1 Generatori di casualità.
E’ probabile che il primo “dado” della storia sia stato un surrogato della moneta nel gioco “testa o croce”; tuttavia questo semplice mezzo per attribuire una precedenza senza conflittualità avrà dimostrato in breve tempo il suo limite – stabilire una preferenza tra due, a meno che si “indica un torneo” con molti lanci e confronti – e sarà stato sostituito da un’altra forma “generatrice di casualità” che permetta rapidamente ordinamenti con più soggetti.
Esempio: sfidanti per la mano della principessa.
a) 2 sfidanti A e B:
- al lancio della moneta 2 possibili risultati: vincente o perdente. Una sola mano stabilisce l’ordinamento casuale tra A e B e la moneta è sufficiente.
b) 3 sfidanti A B e C:
- sono necessari almeno 3 lanci della moneta per stabilire il vincitore:
1) scontro AB
2) scontro AC
3) scontro BC
c) 4 o più sfidanti A B C e D:
- sono necessari almeno 6 lanci (scontri AB AC AD BC BD CD).
Nel caso si usi una qualche specie di dado con 4 facce (un tetragono), è sufficiente un lancio per ciascun partecipante (escludendo sempre i casi di parità) per ottenere una “classifica” che altrimenti necessita 6 lanci di monete.
Aumentando il numero dei partecipanti è ovvia la funzionalità del dado come lo conosciamo (o dei dadi qualora gli sfidanti siano più di 6): invece di molteplici scontri tra 2 sfidanti per volta, una sola sfida tra più partecipanti.
2.1 Perché i dadi che utilizziamo hanno 6 facce?
Abbiamo visto che il dado a 6 facce è uno strumento più efficiente della moneta qualora gli sfidanti siano almeno 4; tuttavia il problema di organizzare un “torneo” si ripropone immediatamente qualora ci siano più di 6 sfidanti (tralasciamo sempre il caso di situazioni di parità).
Una soluzione sarebbe quella di realizzare “dadi” con un numero superiore di facce, usando a tal fine solidi tridimensionali con più lati; tuttavia non abbiamo testimonianze né storiche né recenti di creazioni simili.
Piuttosto è in uso il lancio in contemporanea di 2 o più dadi per ottenere un range più ampio di numeri casuali (nel caso del lancio di 2 dadi il range sarà da 2 – cioè 1+1 – a 12 – cioè 6+6 – e sarà utile per ordinare fino a 11 elementi senza la necessità di organizzare un torneo).
Attenzione però! Usando 2 dadi la probabilità di ottenere con un lancio un numero (somma dei due dadi) da 2 a 12 non è sempre la stessa come nel caso di un solo dado (ottenere uno qualunque dei numeri da 1 a 6 è la stessa): infatti ad es. ottenere 8 è più facile che ottenere 2 o 12 (nel primo caso 8 è il risultato di 2+6, 3+5, 4+4… mentre 2 e 12 sono ottenibili solo con 1+1 e 6+6)
Partiamo da alcune considerazioni.
- Qualsiasi solido lasciato cadere raggiunge uno stato di quiete appoggiando al piano su cui cade una delle sue facce; escludiamo solidi complessi in cui ci siano rientranze o protuberanze per ovvi motivi.
- La casualità del risultato del lancio è garantita dalla simmetria delle facce: durante la rotazione del solido, la simmetria fa sì che non ci siano forze prevalenti (naturalmente nell’ipotesi che la densità del materiale con cui è costruito il dado sia la stessa in ogni sua parte, altrimenti un baricentro spostato favorisce una o più facce rispetto alle altre).
- Non esiste un solido costituito da sole 3 facce; se aggiungiamo una quarta faccia otteniamo un tetraedro, solido simmetrico, con 4 facce eguali.
L’uso di un dado a forma di tetraedro garantisce la casualità in quanto simmetrico, tuttavia abbiamo affermato che lo stato di quiete dopo il lancio viene raggiunto solo quando una delle sue facce aderirà alla superficie del tavolo da gioco; la parte rivolta verso di noi sarà dunque non una faccia ma un vertice.
Nella storia sono stati usati “dadi” a forma di tetraedro (ottenuti da ossa di capra) dove i vertici e non le facce erano numerati, ma sono stati abbandonati ben presto principalmente per due ragioni:
1) servono ad ordinare numeri da 1 a 4 (mentre il dado cubico ordina un intervallo da 1 a 6)
2) un punto (vertice) è meno facile da numerare o identificare rispetto ad una faccia.
Il solido simmetrico successivo al tetraedro è il cubo sul quale sono modellati i dadi come li conosciamo.
Aumentando ancora il numero di facce troviamo altri solidi tridimensionali simmetrici quali l’ottaedro, il dodecaedro e l’icosaedro; tuttavia la realizzazione di “dadi” con la loro forma è più molto più difficile e soggetta ad errori che ne inficiano la simmetria e dunque la “casualità”.
Il dado cubico è dunque il solido simmetrico più facile da realizzare anche per civiltà antiche con pochi mezzi “tecnologici” per garantire una simmetria della forma, e dunque la casualità del risultato di un lancio.
Queste sono in breve le ragioni del suo successo.
NB: possiamo usare come “dadi” tutte le figure simmetriche. Il numero di solidi simmetrici è limitato; rimando allo studio delle simmetrie in dimensioni >3 per la definizione di tutti i tipi di figura simmetrici (cui l’ultimo è il famoso “mostro” che esiste in uno spazio con 196.883 dimensioni e chiude definitivamente l’atlante dei diversi tipi di simmetria esistenti)
3.1 Il significato di dimensioni spaziali ortogonali.
L’argomento di questo breve saggio è analizzare la struttura ed il “funzionamento” di “dadi cubici” realizzati in spazi con dimensioni superiori a 3; poiché l’unica esperienza che ci ritornano i nostri sensi è limitata ad uno spazio a 3 dimensioni, si tratta naturalmente di un gioco concettuale.
Prima di affrontare il problema della costruzione di un dado in 4 o più dimensioni, proviamo a spiegare come si possa “stirare” lo spazio in più dimensioni, ortogonali l’una con l’altra.
Partiamo con l’esempio di una colonia di batteri.
Un singolo batterio può esser considerato (date le sue esigue dimensioni) come un punto geometrico senza dimensioni misurabili.
Supponiamo di inserirlo all’interno di una provetta con una scanalatura molto sottile: il batterio inizierà a sdoppiarsi allungandosi nell’unica direzione libera, e dopo qualche tempo avrà costituito ciò che potremmo definire un segmento di retta (misurabile in una dimensione spaziale).
L’eventuale rottura della provetta causerà una espansione in due direzioni della popolazione batterica sul fondo del contenitore (che immaginiamo a forma di parallelepipedo con base quadrata); otteniamo così una figura piana che può esser misurata in due direzioni ortogonali l’una all’altra.
Una volta occupato tutto il fondo del recipiente, l’aumento della popolazione batterica comporterà un’espansione verso l’alto e l’occupazione di uno spazio tridimensionale, dove anche questa nuova direzione forma angoli retti con le precedenti due.
E poi?
La nostra esperienza si ferma qui, visto che non riusciamo a figurarci ulteriori dimensioni.
Tuttavia nulla ci impedisce di “immaginare” di proseguire l’esperimento in nuove dimensioni ortogonali alle precedenti.
Una descrizione geometrica di questo processo potrebbe essere la seguente:
- Il punto si “stira” verso una direzione e crea un segmento lineare.
- Il segmento si “stira” in una direzione ortogonale alla prima e crea un quadrato
- Il quadrato si “stira” in una terza direzione ortogonale alle 2 date e crea un cubo
- Il cubo si “stira” in una quarta direzione ortogonale alle 3 date e crea un 4-cubo
- Il 4-cubo si “stira” …. ecc. ecc.
Per nostra comodità parleremo di 0-cubo per il punto (cubo a zero dimensioni), di 1-cubo per il segmento, di 2-cubo per il quadrato, di 3-cubo per il cubo di cui abbiamo esperienza diretta e così via (4-cubo, 5-cubo, … n-cubo)
4.1 Com’è fatto l’iperspazio?
Sembra una domanda da “fumetto” o film di fantascienza; l’iperspazio è infatti definito in tali media come qualcosa oltre le 3 dimensioni spaziali cui siamo abituati e generalmente vi sono ambientati universi paralleli, viaggi a velocità iperluminica e tutto quanto contravviene l’esperienza comune e la meccanica classica.
In fisica le dimensioni spaziali necessarie a spiegare il nostro universo sono più di 3 (il tempo indicato come 4^ dimensione nella teoria della relatività non è comunque una dimensione spaziale, ma con le altre 3 costituisce un continuum che non è argomento di questo saggio), tuttavia hanno caratteristiche peculiari (ad esempio una curvatura molto stretta) diverse dalle dimensioni spaziali tra loro ortogonali di cui qui stiamo trattando.
Pur mancando di sensi che ci facciano “vedere” oltre la 3^ dimensione, possiamo “immaginare” oggetti con dimensioni spaziali superiori utilizzando un po’ di buon senso e pochissima matematica.
Nel capitolo precedente abbiamo concluso parlando dello stiramento come processo generatore di ipercubi in una dimensione superiore; sappiamo quindi come generare un (n+1)-cubo dato un n-cubo, ma non abbiamo idea di come questo sia “fatto” se n>3.
4.2 Il caso particolare dell’ipercubo a 4 dimensioni.
Il caso particolare del 4-cubo è raffigurabile con uno stratagemma: anche se non possiamo “vederlo”, possiamo coglierne l’aspetto globale attraverso la sua proiezione (la sua ombra) in uno spazio tridimensionale.
Un 3-cubo può esser rappresentato su una superficie 2d ricavandone un’ombra: in pratica possiamo disegnarne la proiezione su questo foglio (è un’esperienza comune a tutti credo):
una volta disegnato un quadrato (corrispondente alla faccia verso di noi) per rappresentare la 3^ dimensione si fa partire un segmento inclinato da ciascun vertice del 2-cubo (la cui inclinazione e lunghezza dipendono dalla convenzione prospettica adottata), cosicchè da ciascun vertice partano 3 linee, due sul piano ed una che ci da l’illusione di “forare” il foglio e perdersi in profondità.
L’indice dell’esistenza della profondità è per convenzione dato dall’angolo acuto con cui è inclinato il lato che non sta sul foglio (45° nel caso si adotti il criterio dell’assonometria cavaliera).
In fondo si tratta di disegnare un secondo quadrato trascinando una copia del primo muovendosi lungo un segmento che forma un angolo acuto con uno dei lati del quadrato.
Per analogia ripetiamo la stessa esperienza in 3D: trasciniamo un cubo lungo una diagonale interna al cubo 3D ed otteniamo … un cubo dentro un cubo!
Da ogni vertice partiranno 4 spigoli: 3 formeranno angoli di 90° mentre il 4° formerà con essi un angolo acuto a simulare la 4 dimensione (la sua proiezione in 3 dimensioni).
Quali sono le caratteristiche dei cubi a n dimensioni con n>3?
Possiamo intuirlo ricavandolo dalla logica, e cioè esaminando le relazioni tra i cubi a n dimensioni dove n<4 ed estendendo lo stesso ragionamento ai cubi di dimensioni superiori.
4.3 caratteristiche dei cubi ad n. dimensioni
partiamo da uno 0-cubo: il punto. Un solo vertice.
Il passo successivo è un 1-cubo (cioè il segmento): 2 vertici ed un lato (spigolo)
Poi il 2-cubo (il quadrato): 4 vertici, 4 lati
Il 3-cubo (il nostro cubo): 8 vertici, 6 facce, 12 lati.
E poi?
a) numero di vertici: 1,2,4,8, .. sono potenze di 2: 2^n dove n = dimensione del cubo.
Il cubo a 4 dimensioni (ipercubo) avrà 2^4 vertici, e cioè 16
b) spigoli o lati: 0,4,12, …
c) facce: 0,0,1,6, …
Possiamo creare la seguente matrice dove n è il numero di dimensioni del nostro n-cubo ed m quelle di m-cubi dove m<=n
n / m | 0 1 2 3 4 5 6
-------------------------------------------------------------------
0 | 1
1 | 2 1
2 | 4 4 1
3 | 8 12 6 1
4 | 16 32 24 8 1
5 | 32 80 ? 40 10 1
6 | 64 192 ? ? 60 12 1
Significato: la diagonale è per n=m dunque n/m=1
Quando m=n-1 abbiamo una serie dei numeri pari: 2 4 6 sino al 3-cubo. Possiamo pensare che per l’ipercubo ci sia un 8, ecc. ecc. [ se m=n-1 allora i(n-1,n)=n*2 ]
Quando m=n-2 allora i(n-2,n)=n*2*(n-1)
In pratica solo con la logica possiamo riempire la matrice qui sopra.
La formula che la esprima è la seguente:
Qui di seguito il listato di un’applicazione in Vbasic di mia creazione che, dati “n” e “m” risponde alla domanda: “quanti m-cubi stanno in un n-cubo dove m<=n”:
Rem cubi
inizio:
input "n=";n
input "m=";m
If m > n Then Print "Errore": Clear: GoTo inizio
Dim y(n + 1, m + 1)
For c = 0 To n: y(c, 0) = 1: Next c
For c = 1 To n
For d = 1 To m
If d > c Then GoTo prossimoc
y(c, d) = y(c - 1, d - 1) + y(c - 1, d)
Next d
prossimoc:
Next c
x = y(n, m) * 2 ^ (n - m)
Print "Risultato";
Print x
input "Nuovo calcolo";a$
If a$ = "S" Or a$ = "s" Or a$ = "" Then Clear: GoTo inizio
End
Usando questa semplice applicazione, possiamo descrivere le principali caratteristiche di dadi di ogni dimensione.
5.1 Il dado tridimensionale di cui abbiamo esperienza comune.
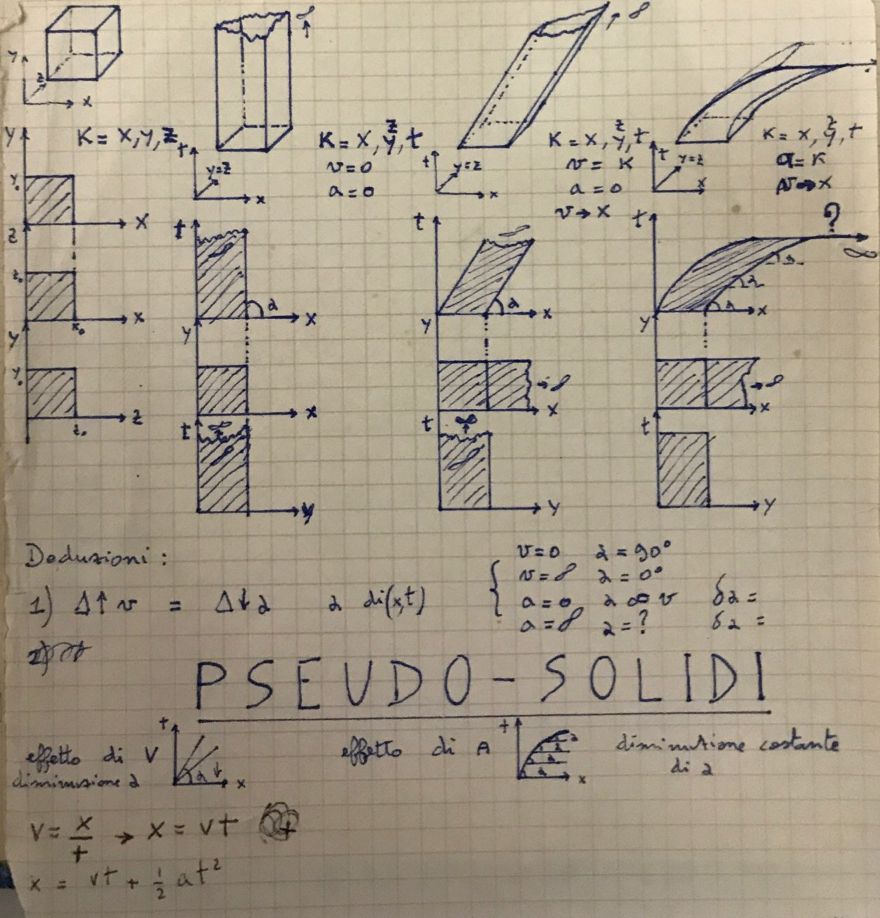
Possiamo definire il dado come un cubo a 3 dimensioni che, lanciato da una mano in una porzione di spazio tridimensionale, viene lasciato cadere su una superficie piana dove rimbalza ruotando sui propri 2 assi e dopo un percorso si “ferma” presentando una delle sue sei facce verso “l’alto”. Ogni faccia è identificata (da un numero o da un colore) che rappresenta il valore casuale selezionato.
Proviamo a descrivere questa esperienza in altro modo:
Il dado è un generatore di numeri casuali nell’intervallo da 1 a 6
Consiste in un cubo ad n-dimensioni costituito da 6 cubi ad n-1 dimensioni: in base alla formula spiegata nel capitolo precedente, esiste solo un n-cubo che soddisfi questa condizione, quello dove n=3
Per compiere la propria funzione, viene lasciato cadere dall’alto verso il basso all’interno di uno spazio tridimensionale: durante la caduta può ruotare intorno ad uno dei suoi due assi (alto-basso, sinistra-destra) oppure a tutti e due.
Il movimento dall’alto verso il basso termina con uno o più rimbalzi su una superficie a n-1 dimensioni (nel nostro caso un piano bidimensionale).
La forza impressa dal lancio e dalla gravità ad un certo punto si esaurisce e le rotazioni ed i rimbalzi terminano quando il dado raggiunge uno stato di quiete .
Tale stato di quiete si esprime con l’adiacenza di una faccia (cubo ad n-1 dimensioni) ad una parte del piano (figura a n-1 dimensioni).
Il numero casuale generato è quello corrispondente alla faccia opposta (al suo cubo n-1 dimensioni simmetrico rispetto al centro del cubo ad n dimensioni).
6. Un dado in uno spazio n-dimensionale
Il concetto di dado, quale lo abbiamo definito, può essere espresso in uno spazio a qualsivoglia numero di dimensioni: assolverà sempre la sua funzione di generatore di casualità.
6.1 Giocare con un dado a 1 dimensione.
Un segmento ha 2 vertici che possiamo numerare.
6.2 Giocare con un dado a 2 dimensioni
Un dado a due dimensioni è un quadrato con 4 lati, dunque 4 facce (vengono generati numeri da 1 a 4)
La caduta avviene dal bordo del foglio superiore a quello inferiore, e viene interrotta da un segmento sul quale il quadrato rimbalza.
L’unico tipo di rivoluzione che possiamo imprimere nel corso della caduta è quella intorno al proprio centro (del tipo destra-sinistra).
Quiete: se la gravità preme dall’alto verso il basso del foglio, lo stato di quiete del nostro dado viene raggiunto quando una delle facce risulta adiacente al segmento (parziale sovrapposizione di due figure 1-dimensionali).
Il numero casuale generato sarà quello assegnato al segmento opposto (quello rivolto verso l’alto del foglio)
Se definiamo lo stato di quiete come l’adiacenza di un lato del quadrato al segmento, l’operazione di tirare un dado bidimensionale coincide con il far ruotare il quadrato con i lati numerati da 1 a 4 sul segmento fino a che, dopo un certo percorso più o meno lungo a seconda della forza impressa inizialmente e dell’attrito esercitato dal segmento (e dall’aria) sui vertici e poi sui bordi del quadrato, il quadrato si ferma con un lato adiacente al segmento.
Poiché la gravità si esercita in uno spazio bidimensionale dall’alto verso il basso, non può rimanere in bilico su uno spigolo.
Il numero ”sorteggiato”, >0 e <5 sarà quello assegnato al lato in alto del quadrato.
6.3 Giocare con un dado a 3 dimensioni
I dadi che siamo soliti usare hanno 3 dimensioni e coincidono con la rappresentazione geometrica di un cubo: 8 vertici, 6 facce quadrate bidimensionali.
La rivoluzione che possiamo imprimere avviene secondo due assi
Il rimbalzo può cambiare l’asse di rivoluzione (es. nord-sud con est-ovest)
Tradizionalmente sono numerate le facce (che possiamo definire cubi ad n-1 dimensioni, dove il dado è un cubo a dimensione 3 e le sue 6 facce sono cubi a 3-1=2 dimensioni, cioè quadrati).
6 facce = 6 numeri.
Il dado-cubo rimbalza su una superificie piana (cubo ad n-1 dimensioni)
Rimbalza su questa superficie ed il suo stato di quiete coincide con l’adiacenza di una faccia del dado con il piano.
Il numero vincente è quello assegnato alla superficie opposta a quella adiacente.
6.4 Giocare con un dado a 4 dimensioni
I nostri sensi ci impediscono di visualizzare una figura quadridimensionale tipo il cubo a 4 dimensioni che potrebbe costituire il nostro dado 4d
Per intuizione, se il dado 2d ha 4 facce numerabili (4 lati del quadrato) ed il dado 3d ha 6 facce (6 quadrati come lati del cubo3d) il dado 4d avrà 8 facce numerabili; non si tratterà di facce lineari come nel caso del dado 2d né piane come nel caso del dado 3d, ma di 8 facce a forma di 3-cubo che costituiscono i lati del 4-cubo.
Ad ogni 3-cubo assegneremo un numero da 1 a 8.
La rivoluzione avverrà intorno a 3 assi (destra-sinistra, basso-alto, ?-?)
Il rimbalzo avverrà su una superficie 3d quale un cubo e lo stato di quiete si avrà quando una faccia cubica del dado 4d sarà adiacente al cubo 3d che ne costituisce la superficie di appoggio
Luogo di adiacenza.
Per ipotesi supponiamo che la dimensione del “lato” del dado sia 1/2 della superficie di appoggio
Nel caso del cubo 2d, il segmento “lato” risulta adiacente alla parte centrale del segmento “base”
Nel caso del cubo 3d, il quadrato “lato” risulta adiacente alla parte centrale del quadrato “base”
Nel caso del cubo 4d, il cubo “lato” risulta adiacente alla parte centrale di ogni faccia del cubo.
Qui di seguito un tentativo di rappresentazione grafica dell’adiacenza in stato di quiete.
Lo stesso gioco può esser ripetuto con n-cubi in ogni dimensione.
Ora la sfida è creare un “videogioco” che ci permetta di giocare con un 4-cubo come dado 4d: dobbiamo poter seguire ogni suo movimento attraverso la proiezione su uno spazio tridimensionale (come abbiamo visto nel capitolo 4.2).
Continua ….